Solution
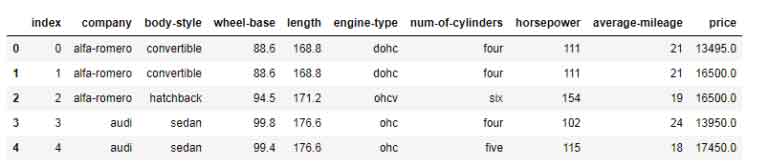
First five rows
import pandas as pd
df = pd.read_csv("D:\\DZONE\\Python\\pandas\\Cars_Data.csv")
df.head(5)
Result
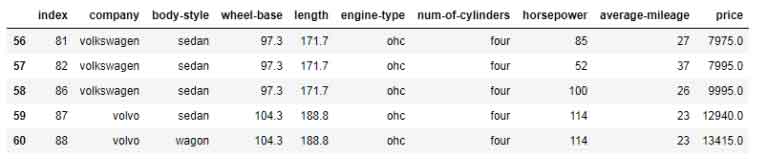
Last Five Rows
df.tail(5)
Result
Solution
df = pd.read_csv("D:\\DZONE\\Python\\pandas\\Cars_Data.csv", na_values={
'price':["?","n.a"],
'stroke':["?","n.a"],
'horsepower':["?","n.a"],
'peak-rpm':["?","n.a"],
'mileage':["?","n.a"]})
print (df)
df.to_csv("D:\\DZONE\\Python\\pandas\\Cars_Data.csv")
Find Car Firm with highest rate
Solution
df = pd.read_csv("D:\\DZONE\\Python\\pandas\\Cars_Data.csv")
df = df [['brand','price']][df.price==df['price'].max()]
print(df)
o/p
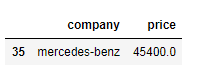
Solution
df = pd.read_csv("D:\\DZONE\\Python\\pandas\\Cars_Data.csv")
car_Comp = df.groupby('brand')
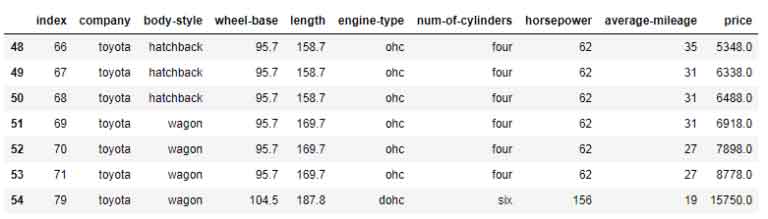
nisDf = car_Comp.get_group('nissan')
print(nisDf)
o/p
Solution
df = pd.read_csv("D:\\DZONE\\Python\\pandas\\Cars_Data.csv")
df['brand'].value_counts()
o/p
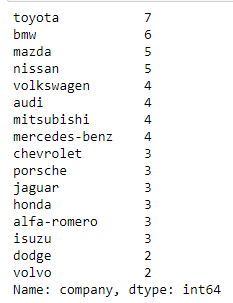
Solution
df = pd.read_csv("D:\\DZONE\\Python\\pandas\\Cars_Data.csv")
car_comp = df.groupby('brand')
priceDf = car_comp['brand','price'].max()
priceDf
Result
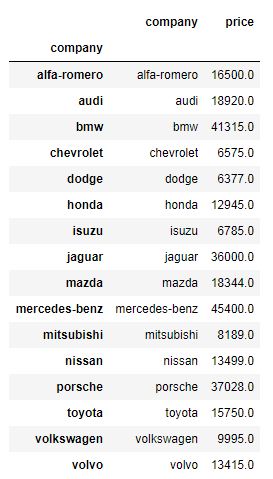
o/p
df = pd.read_csv("D:\\DZONE\\Python\\pandas\\Cars_Data.csv")
carComp = df.groupby('brand')
mDf = carComp['brand','mileage'].mean()
print(mDf)
Result
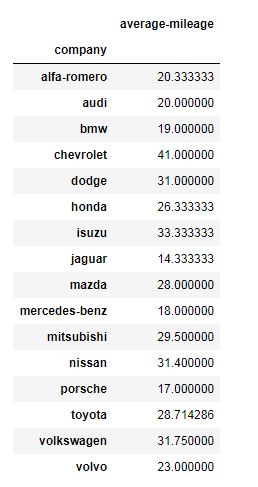
o/p
Df = pd.read_csv("D:\\DZONE\\Python\\pandas\\Cars_Data.csv")
Df = Df.sort_values(by=['price', 'horsepower'], ascending=False)
Df.head(5)
Result
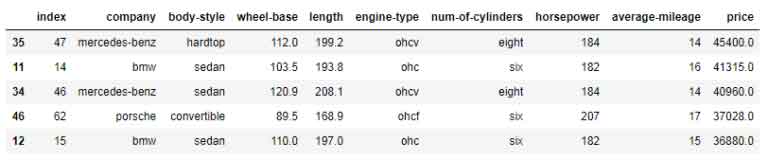
-
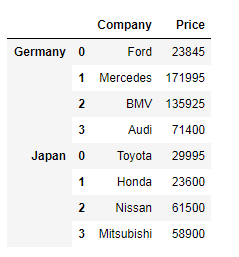
G_Comp = {'Firm': ['Hundai', 'Mazda', 'jaguar', 'Porsche'], 'Price': [18752, 127850, 356982 , 56892]}
J_Comp = {'Firm': ['Porsche', 'Honda', 'Nissan', 'volkswagen'], 'Price': [41781, 25841, 83256 , 56781]}
O/p
G_Comp = {'Firm': ['Hundai', 'Mazda', 'jaguar', 'Porsche'], 'Price': [18752, 127850, 356982 , 56892]}
carsDf1 = pd.DataFrame.from_dict(G_Comp)
J_Comp = {'Firm': ['Porsche', 'Honda', 'Nissan', 'volkswagen'], 'Price': [41781, 25841, 83256 , 56781]}
carsDf2 = pd.DataFrame.from_dict(J_Comp)
carsDf = pd.concat([carsDf1, carsDf2], keys=["Russia", "India"])
print(carsDf)
Result
Create two data frames using following two Dicts, Merge two data frames, and append second data frame as a new column to first data frame.
Price = {'Firm': ['Hundai', 'Honda', 'Chevrolet', 'Porsche'], 'Price': [18752, 17995, 356982 , 56892]}
Hpower = {'Firm': ['Hundai', 'Honda', 'Chevrolet', 'Porsche'], 'horsepower': [141, 80, 182 , 160]}
Code
Price = {'Firm': ['Hundai', 'Honda', 'Chevrolet', 'Porsche'], 'Price': [18051, 17095, 450982 , 50392]}
pDf = pd.DataFrame.from_dict(Price)
Hpower = {'Firm': ['Hundai', 'Honda', 'Chevrolet', 'Porsche'], 'horsepower': [132, 90, 172 , 150]}
hDf = pd.DataFrame.from_dict(Hpower)
carsDf = pd.merge(pDf, hDf, on="Firm")
carsDf
Result





